DevOps & SysOps engineer with over 12 years of experience in cloud,
virtualization and distributed systems.
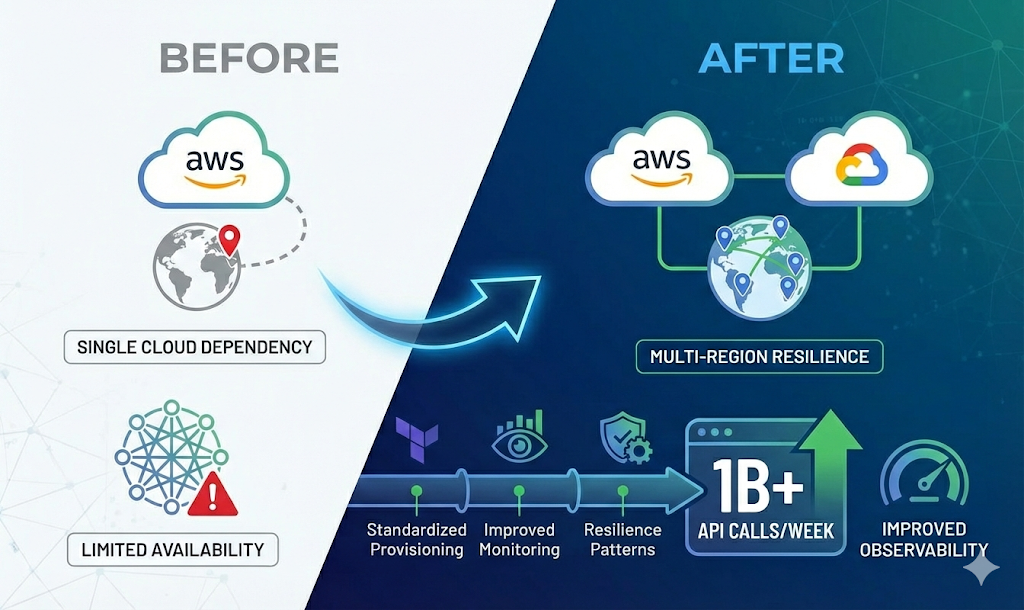
Strong expertise in AWS, GCP, Kubernetes and on-prem infrastructures
(vSphere, Proxmox, Ceph), with a solid background in security,
databases and high availability architectures.
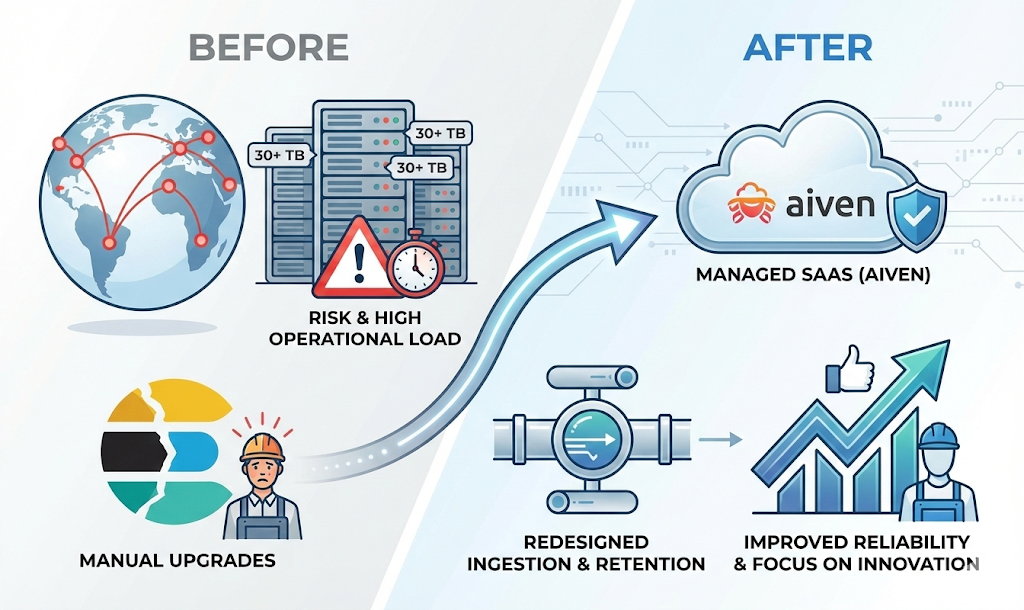
I have led and contributed to large-scale platforms serving
millions of requests per day, focusing on stability, scalability
and operational excellence.
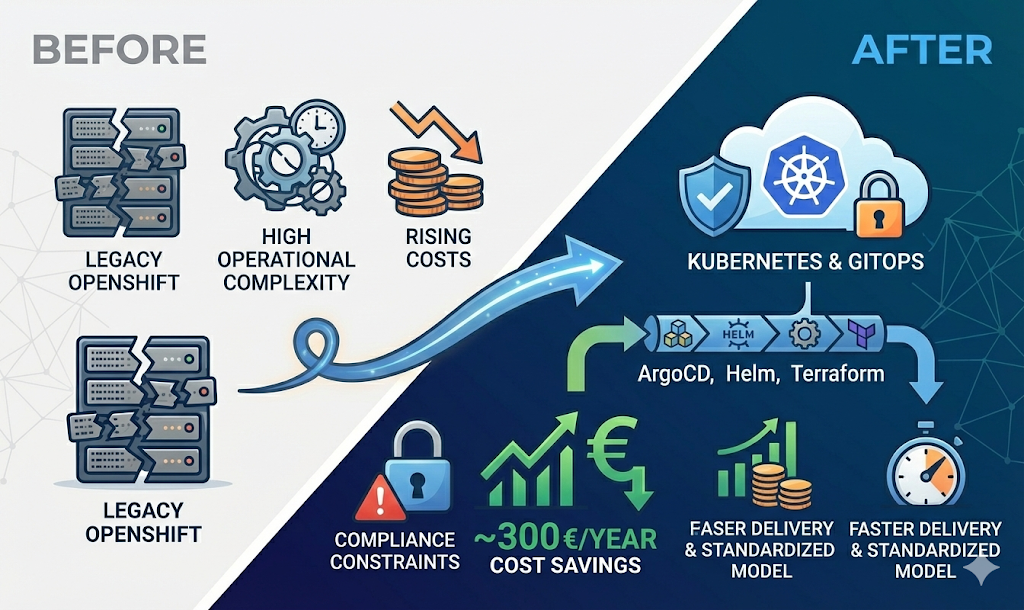
- Kubernetes (GKE, EKS, RKE)
- Terraform & Infrastructure as Code
- AWS & GCP
- Proxmox, vSphere, Ceph
- Observability (Prometheus, Grafana, ELK)
- Security & Networking